本文主要介绍了C#使用Tesseract进行Ocr识别的方法实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
1.Nuget搜索Tesseract
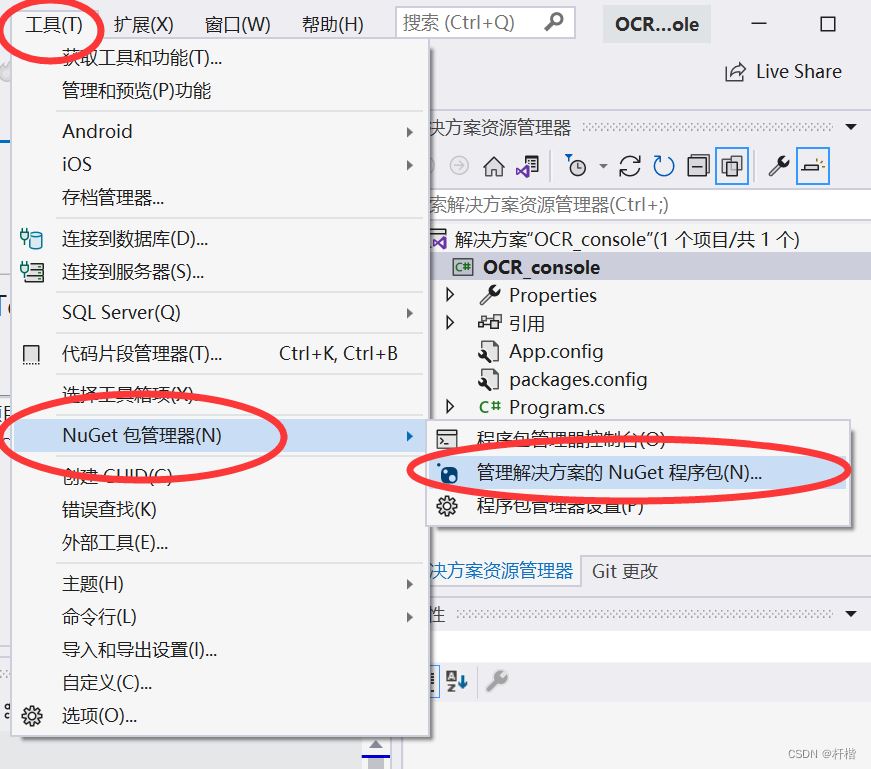
2.项目安装Tesseract
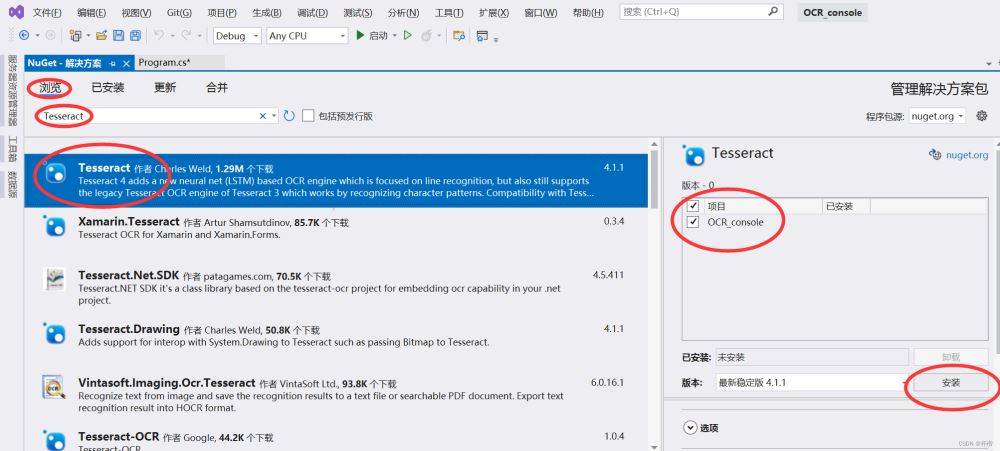
3.引用命名空间
using Tesseract;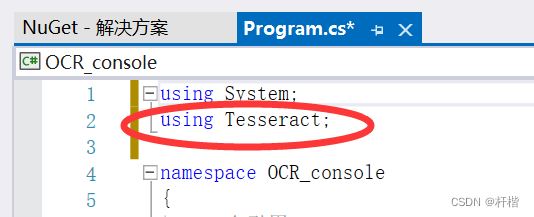
4.上Github下载别人的训练库
https://github.com/tesseract-ocr/tessdata 这里下载中文的chi_sim.traineddata,放到了D盘根目录
5.选择图片进行识别
我把图片命名为image.jpg放在了D盘根目录
//图片文件路径
string imageFileName = @"D:\image.png";
//创建位图对象
Bitmap image = new Bitmap(imageFileName);
//Tesseract.Page
Page page = new TesseractEngine(@"D:\", "chi_sim", EngineMode.Default).Process(PixConverter.ToPix(image));
//释放程序对图片的占用
image.Dispose();
//打印识别率
Console.WriteLine(String.Format("{0:P}", page.GetMeanConfidence()));
//打印识别文本 //替换'/n'为'(空)'//替换'(空格)'为'(空)'
Console.WriteLine(page.GetText().Replace("\n", "").Replace(" ", ""));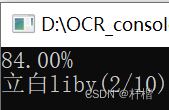
识别率为百分之84,识别文字为立白liby
到此这篇关于C#使用Tesseract进行Ocr识别的方法实现的文章就介绍到这了,更多相关C# Ocr识别内容请搜索得得之家以前的文章希望大家以后多多支持得得之家!
沃梦达教程
本文标题为:C#使用Tesseract进行Ocr识别的方法实现


基础教程推荐








猜你喜欢
- C#使用NPOI将excel导入到list的方法 2023-05-22
- 浅谈C# 构造方法(函数) 2023-03-03
- C#中参数的传递方式详解 2023-06-27
- Unity虚拟摇杆的实现方法 2023-02-16
- 如何用C#创建用户自定义异常浅析 2023-04-21
- C# TreeView从数据库绑定数据的示例 2023-04-09
- C#执行EXE文件与输出消息的提取操作 2023-04-14
- C#使用Chart绘制曲线 2023-05-22
- C#实现归并排序 2023-05-31
- C#使用SQL DataAdapter数据适配代码实例 2023-01-06