MongoDB 中使用聚合(Aggregations)来分析数据并从中获取有意义的信息,本文重点给大家介绍SpringBoot系列之MongoDB Aggregations用法,感兴趣的朋友跟随小编一起看看吧
1、前言
在上一章的学习中,我们知道了Spring Data MongoDB的基本用法,但是对于一些聚合操作,还是不熟悉的,所以本博客介绍一些常用的聚合函数
2、什么是聚合?
MongoDB 中使用聚合(Aggregations)来分析数据并从中获取有意义的信息。在这个过程,一个阶段的输出作为输入传递到下一个阶段
常用的聚合函数
| 聚合函数 | SQL类比 | 描述 |
|---|---|---|
| project | SELECT | 类似于select关键字,筛选出对应字段 |
| match | WHERE | 类似于sql中的where,进行条件筛选 |
| group | GROUP BY | 进行group by分组操作 |
| sort | ORDER BY | 对应字段进行排序 |
| count | COUNT | 统计计数,类似于sql中的count |
| limit | LIMIT | 限制返回的数据,一般用于分页 |
| out | SELECT INTO NEW_TABLE | 将查询出来的数据,放在另外一个document(Table) , 会在MongoDB数据库生成一个新的表 |
3、环境搭建
- 开发环境
- JDK 1.8
- SpringBoot2.2.1
- Maven 3.2+
- 开发工具
- IntelliJ IDEA
- smartGit
- Navicat15
使用阿里云提供的脚手架快速创建项目:
https://start.aliyun.com/bootstrap.html
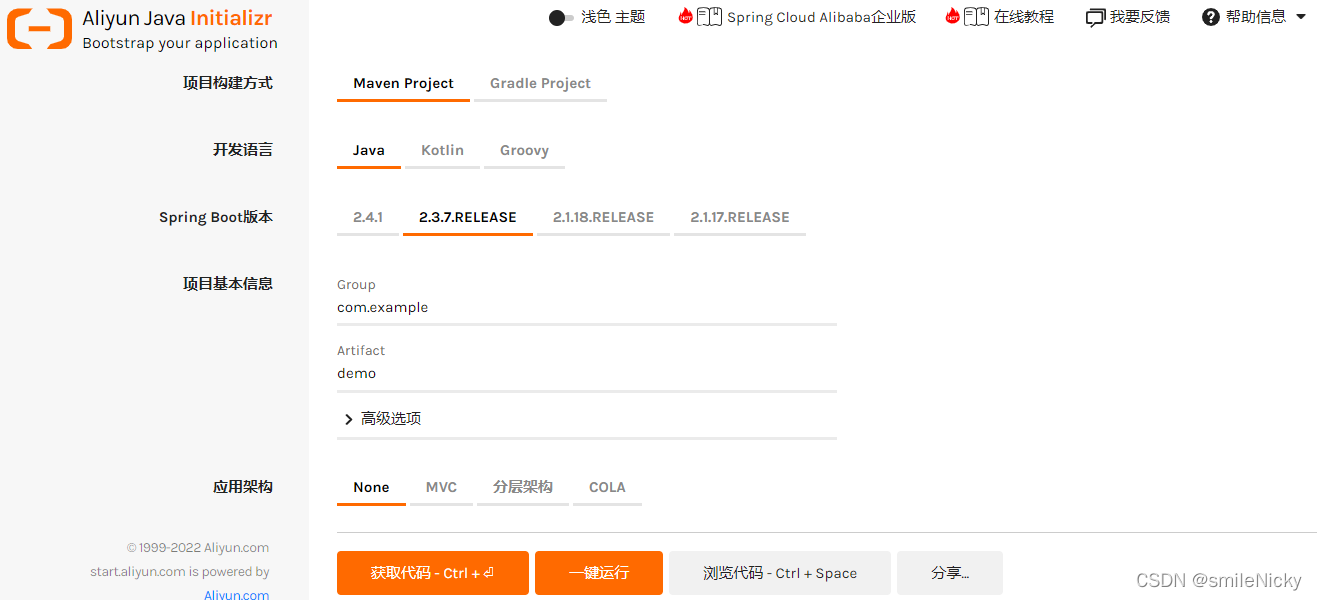
也可以在idea里,将这个链接复制到Spring Initializr这里,然后创建项目
jdk选择8的
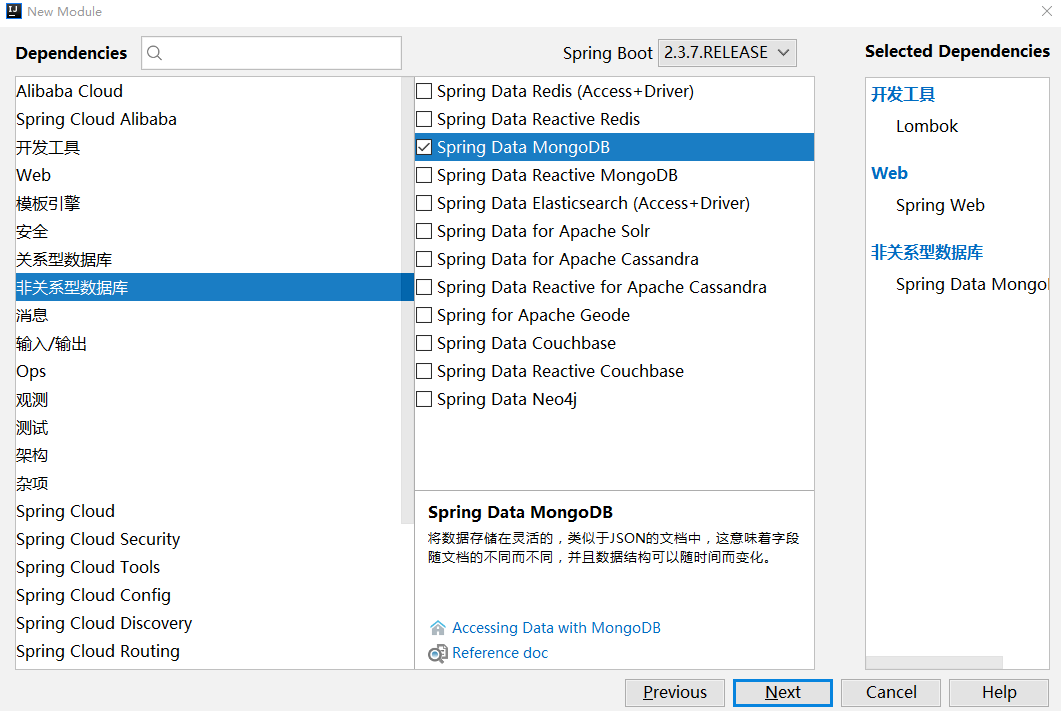
选择spring data MongoDB
4、数据initialize
private static final String DATABASE = "test";
private static final String COLLECTION = "user";
private static final String USER_JSON = "/userjson.txt";
private static MongoClient mongoClient;
private static MongoDatabase mongoDatabase;
private static MongoCollection<Document> collection;
@BeforeClass
public static void init() throws IOException {
mongoClient = new MongoClient("192.168.0.61", 27017);
mongoDatabase = mongoClient.getDatabase(DATABASE);
collection = mongoDatabase.getCollection(COLLECTION);
collection.drop();
InputStream inputStream = MongodbAggregationTests.class.getResourceAsStream(USER_JSON);
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
reader.lines()
.forEach(l->collection.insertOne(Document.parse(l)));
reader.close();
}5、例子应用
本博客,不每一个函数都介绍,通过一些聚合函数配置使用的例子,加深读者的理解
统计用户名为User1的用户数量
@Test
public void matchCountTest() {
Document first = collection.aggregate(
Arrays.asList(match(Filters.eq("name", "User1")), count()))
.first();
log.info("count:{}" , first.get("count"));
assertEquals(1 , first.get("count"));
}skip跳过记录,只查看后面5条记录
@Test
public void skipTest() {
AggregateIterable<Document> iterable = collection.aggregate(Arrays.asList(skip(5)));
for (Document next : iterable) {
log.info("user:{}" ,next);
}
}对用户名进行分组,避免重复,group第一个参数$name类似于group by name,调用Accumulators的sum函数,其实类似于SQL,SELECT name ,sum(1) as sumnum FROMusergroup by name
@Test
public void groupTest() {
AggregateIterable<Document> iterable = collection.aggregate(Arrays.asList(
group("$name" , Accumulators.sum("sumnum" , 1)),
sort(Sorts.ascending("_id"))
));
for (Document next : iterable) {
log.info("user:{}" ,next);
}
}参考资料
MongoDB 聚合 https://www.runoob.com/
MongoDB Aggregations Using Java
到此这篇关于SpringBoot系列之MongoDB Aggregations用法的文章就介绍到这了,更多相关SpringBoot MongoDB Aggregations用法内容请搜索编程学习网以前的文章希望大家以后多多支持编程学习网!
本文标题为:SpringBoot系列之MongoDB Aggregations用法详解


基础教程推荐








- 如何保障mysql和redis之间的数据一致性 2024-04-25
- mysql时间字段默认设置为当前时间实例代码 2022-08-31
- mysql服务启动却连接不上的解决方法 2023-12-08
- Redis配置项汇总 2024-04-04
- MySQL索引优化之适合构建索引的几种情况详解 2023-12-29
- Mysql查看死锁与解除死锁的深入讲解 2024-02-14
- Redis GEORADIUS命令 2024-04-06
- 浅谈数据库优化方案 2024-02-16
- 详解Redis连接命令使用方法 2024-03-23
- SQL Server之SELECT INTO 和 INSERT INTO SELECT案例详解 2024-02-13








