MySQL索引优化之分页探索详细介绍 目录 MySQL索引优化之分页探索 案例一 案例二 MySQL索引优化之分页探索 表结构 CREATE TABLE `demo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' C
目录
- MySQL索引优化之分页探索
- 案例一
- 案例二
MySQL索引优化之分页探索
表结构
CREATE TABLE `demo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '职位',
`card_num` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '工卡号',
PRIMARY KEY (`id`),
KEY `index_union` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=450003 DEFAULT CHARSET=utf8;
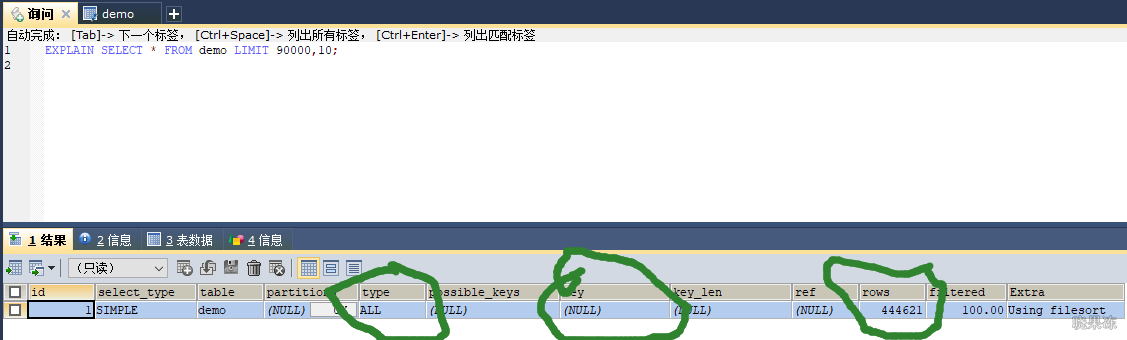
450003条数据limit分页执行情况
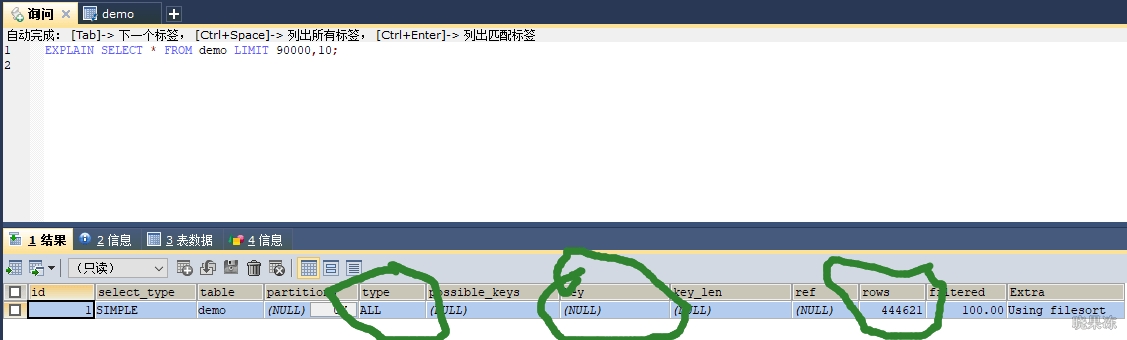
像select * from demo limit 90000,10;考虑到回表,所以mysql干脆选择全表扫描。
mysql不是直接从第90000行开始计算10条,而是从第一个叶子节点开始计数,计算90010行。
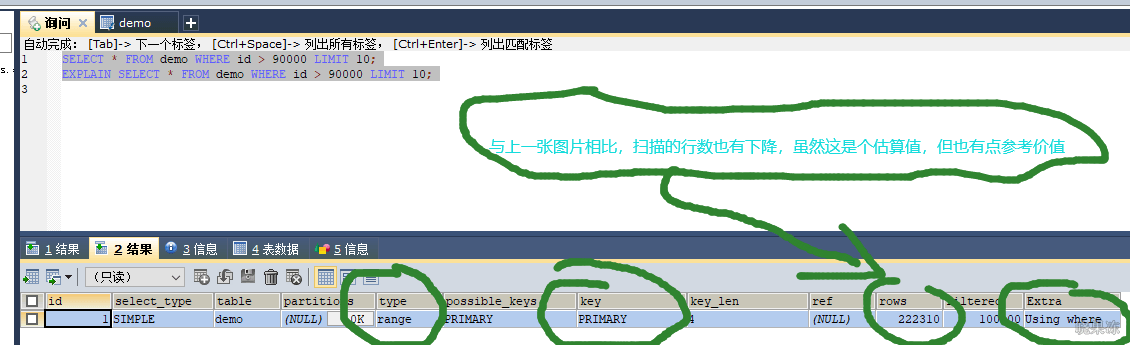
案例一
针对上图,当id是连续自增的时候,可以用主键筛选出id=90000之后的数据。因为主键的索引是B+树结构,本身就是有序的。
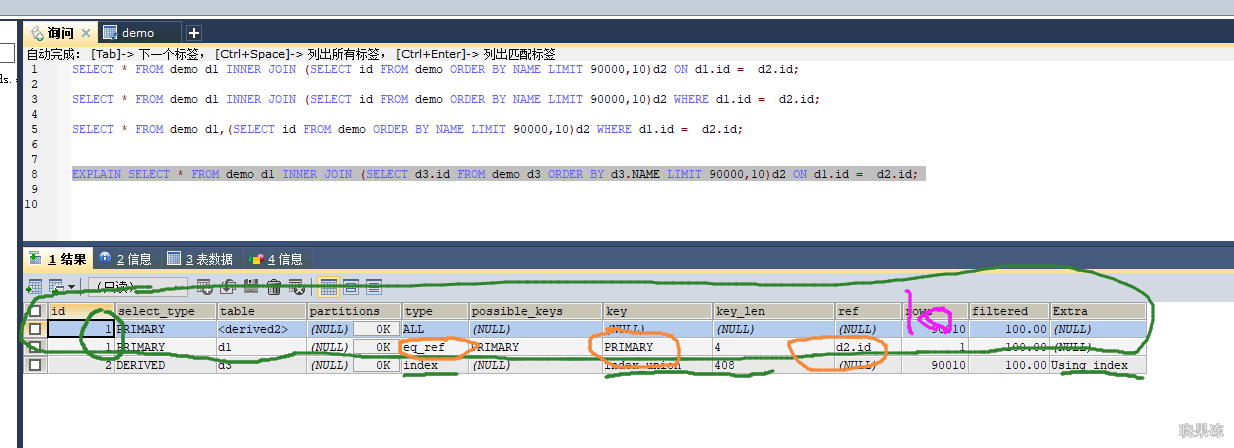
案例二

先按照name排序,然后再从第90000行起找10行,虽然name是索引,但select的列在index_union索引树上并没有保存。
所以还会涉及到回表,于是mysql直接选择扫主键索引树的叶子结点,先将40多万数据根据name排好序,然后计算90000行+10行。
优化方法:利用子查询解决最消耗时间的排序和回表问题,联合索引树种保存有主键id,order by name的话可以将name、age、position整个索引充分使用因为确定了最左列的排序,其余的俩列age、和position其实也是
排好序的了,通过Extra字段也可以是使用了索引树做排序。
最外层的查询是根据主键来关联的,所以几乎可以忽略。10+10 因为id是主键,可以直接拿临时表10条数据去扫。
到此这篇关于MySQL索引优化之分页探索详细介绍的文章就介绍到这了,更多相关MySQL分页探索内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本文标题为:MySQL索引优化之分页探索详细介绍


基础教程推荐








- mysql服务启动却连接不上的解决方法 2023-12-08
- Mysql查看死锁与解除死锁的深入讲解 2024-02-14
- 详解Redis连接命令使用方法 2024-03-23
- Redis配置项汇总 2024-04-04
- 如何保障mysql和redis之间的数据一致性 2024-04-25
- MySQL索引优化之适合构建索引的几种情况详解 2023-12-29
- 浅谈数据库优化方案 2024-02-16
- SQL Server之SELECT INTO 和 INSERT INTO SELECT案例详解 2024-02-13
- Redis GEORADIUS命令 2024-04-06
- mysql时间字段默认设置为当前时间实例代码 2022-08-31








