命令请求的执行过程一个命令请求从发送到获得回复的过程中,客户端和服务器需要完成一系列操作。举个栗子,如果我们使用客户端执行以下命令:127.0.0.1:6379 SET KEY VALUEOK那么客户端发送SET KEY VALUE命令到获...

命令请求的执行过程
一个命令请求从发送到获得回复的过程中,客户端和服务器需要完成一系列操作。举个栗子,如果我们使用客户端执行以下命令:
127.0.0.1:6379> SET KEY VALUE OK
那么客户端发送SET KEY VALUE命令到获得回复OK期间,客户端和服务端共需要执行以下操作:
- 客户端向服务器发送命令请求SET KEY VALUE
- 服务器接收并处理客户端的命令请求SET KEY VALUE,在数据库中进行设置操作,并产生命令回复OK
- 服务器将命令回复OK发送给客户端
- 客户端接收服务器返回的命令回复OK,并将这个回复打印给用户看
发送命令请求
Redis服务器的命令请求来自Redis客户端,当用户在客户端中键入一个命令请求时,客户端会将这个命令请求转换成协议格式,然后通过连接到服务器的套接字,将协议格式的命令请求发送给服务器,如图1-1所示

图1-1 客户端接收并发送命令请求的过程
举个栗子,假设用户在客户端键入命令:
SET KEY VALUE
那么客户端会将这个命令转换成协议:
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
然后将这段协议发送给服务器
读取命令请求
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时,服务器将调用命令请求处理器来执行以下操作:
- 读取套接字中协议格式的命令请求,并将其保存到客户端状态的输入缓冲区
- 对输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数,以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的argv和argc属性
- 调用命令执行器,执行客户端指定的命令
继续以上一小节的SET命令为例子,图1-2展示了程序将命令请求保存到客户端状态的输入缓冲区,客户端状态的样子
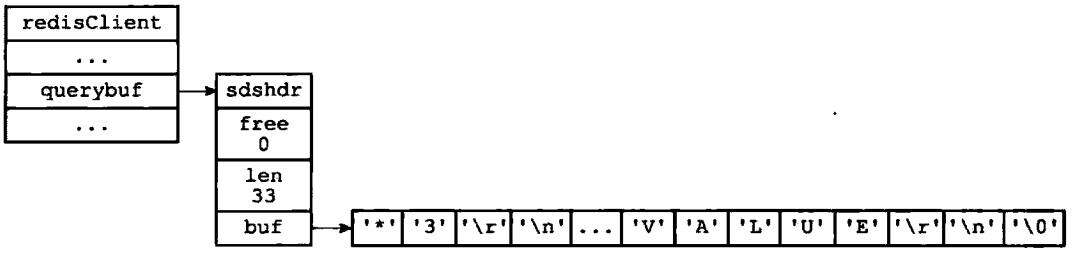
图1-2 客户端状态中的命令请求
之后,分析程序两对输入缓冲区的协议进行分析:
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
并将得出的分析结果保存到客户端状态的argv属性和argc属性,如图1-3所示

图1-3 客户端状态的argv属性和argc属性
之后,服务器将通过调用命令执行器来完成执行命令所需的余下步骤,以下几个小节将分别介绍命令执行器所执行的工作
命令执行器(1):查找命令实现
命令执行器要做的第一件事就是根据客户端状态的argv[0]参数,在命令表中查找参数所指定的命令,并将找到的命令保存到客户端状态的cmd属性中。命令表是一个字典,字典的键是一个个命令名字,比如"set"、"get"、"del"等等;而字典的值则是一个个redisCommand结构体,每个redisCommand结构体记录了一个Redis命令的实现信息,表1-1记录了这个结构体的各个主要属性的类型和作用
| 属性名 | 类型 | 作用 |
| name | char * | 命令的名字,比如"set" |
| proc | redisCommandProc * | 函数指针,指向命令的实现函数,比如setCommand。redisCommandProc类型的定义为typedef void redisCommandProc(redisClient *c) |
| arity | int |
命令参数的个数,用于检查命令请求的格式是否正确。如果这个值为负数-N,那么表示参数的数量大于等于N。注意命令的名字本身也是一个参数,比如说SET msg "hello world 命令的参数是"SET"、"msg"、"hello world",而不仅仅是"msg"和"hello world" |
| sflags | char * | 字符串形式的标识值,这个值记录了命令的属性,比如这个命令是写命令还是读命令, 这个命令是否允许在载入数据时使用,这个命令是否允许在 Lua 脚本中使用,等等 |
| flags | int | 对sflags标识进行分析得出的二进制标识,由程序自动生成。服务器对命令标识进行检查时使用的都是flags属性而不是 sflags属性,因为对二进制标识的检查可以方便地通过&、^、~等操作来完成 |
| calls | long long | 服务器总共执行了多少次这个命令 |
| milliseconds | long long | 服务器执行这个命令所耗费的总时长 |
表1-2列出了sflags属性可以使用的标识值,以及这些标识的意义
| 标识 | 意义 | 带有这个标识的命令 |
| w | 这是一个写入命令,可能会修改数据库 | SET、RPUSH、DEL等等 |
| r | 这是一个只读命令,不会修改数据库 | GET、STRLEN、EXISTS,等等 |
| m | 这个命令可能会占用大量内存, 执行之前需要先检查服务器的内存使用情况,如果内存紧缺的话就禁止执行这个命令 | SET、APPEND、RPUSH、LPUSH、SADD、SINTERSTORE,等等 |
| a | 这是一个管理命令 | SAVE、BGSAVE、SHUTDOWN ,等等 |
| p | 这是一个发布与订阅功能方面的命令 | PUBLISH、SUBSCRIBE、PUBSUB,等等 |
| s | 这个命令不可以在Lua脚本中使用 | BRPOP、BLPOP、BRPOPLPUSH、SPOP,等等 |
| R | 这是一个随机命令,对于相同的数据集和相同的参数,命令返回的结果可能不同 | SPOP、SRANDMEMBER、SSCAN、RANDOMKEY,等等 |
| S | 当在Lua脚本中使用这个命令时,对这个命令的输出结果进行一次排序,使得命令的结果有序 | SINTER、SUNION、SDIFF、SMEMBERS、KEYS,等等 |
| l | 这个命令可以在服务器载入数据的过程中使用 | INFO、SHUTDOWN、PUBLISH,等等 |
| t | 这是一个允许从服务器在带有过期数据时使用的命令 | SLAVEOF、PING、INFO,等等 |
| M | 这个命令在监视器(monitor)模式下不会自动被传播(propagate) | EXEC |
图1-4展示了命令表的样子,并以SET命令和GET命令作为例子,展示了redisCommand结构体:
- SET命令的名字为"set",实现函数为setCommand;命令的参数为-3,表示命令接受三个或以上数量的参数;命令的标识为"wm",表示SET命令是一个写入命令,并且在执行这个命令之前,服务器应该对占用内存状态进行检查,因为这个命令可能会占用大量内存
- GET命令的名字为"get",实现函数为getCommand函数;命令的参数个数为2,表示命令只接受两个参数;命令的标识为"r",表示这是一个只读命令
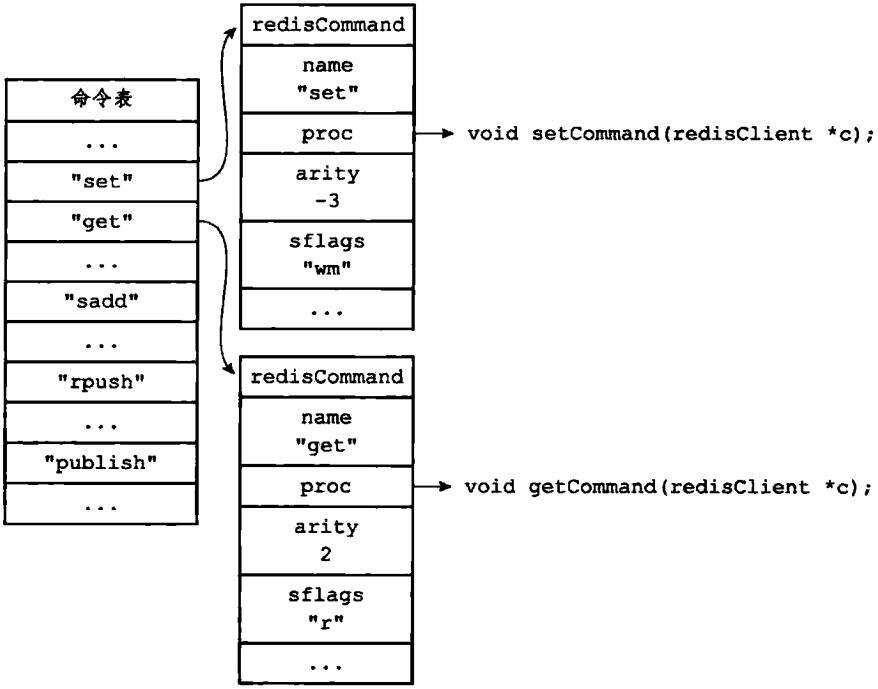
图1-4 命令表
继续之前SET命令的例子,当程序以图1-3中的argv[0]作为输入,在命令表中进行查找时,命令表将返回"set"键所对应的redisCommand结构体,客户端状态的cmd指针会指向这个redisCommand结构体,如图1-5所示
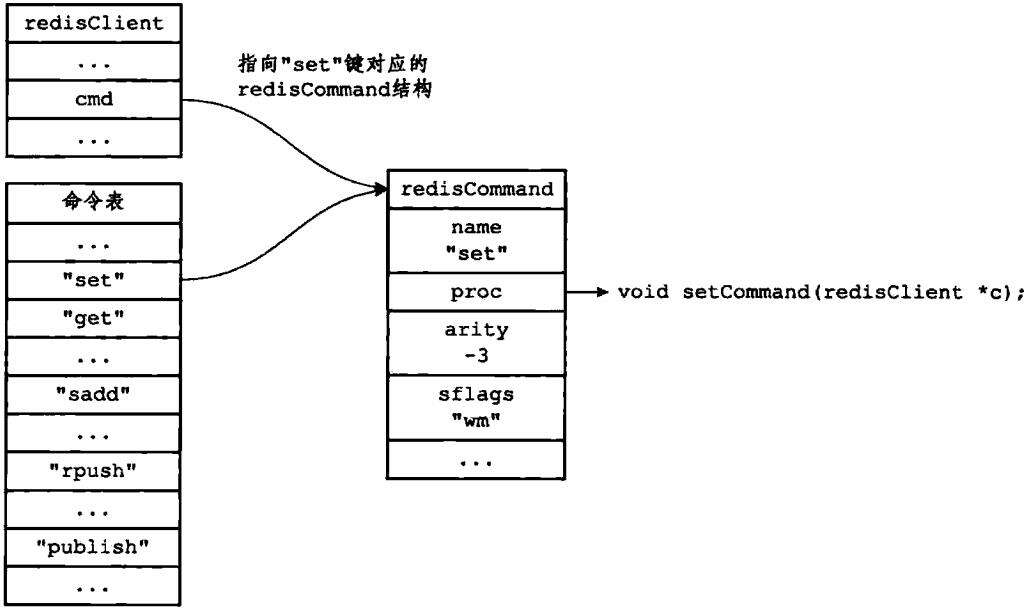
图1-5 设置客户端状态的cmd指针
命令执行器(2):执行预备操作
到目前为止,服务器已经将执行命令所需的命令实现函数(保存在客户点状态的cmd属性)、参数(保存在客户端状态的argv属性)、参数个数(保存在客户端状态的argc属性)都收集齐了,但在真正执行命令前,程序还需要进行一些预备操作,从而确保命令可以正确、顺利地被执行,这些操作包括:
- 检查客户端状态的cmd指针是否执行NULL,如果是的话,那么说明客户端输入的命令名字找不到相应的命令实现,服务器不再执行后续步骤,并向客户端返回一个错误
- 根据客户端cmd属性指向的redisCommand结构体的arity属性,检查命令请求所给定的参数个数是否正确,当参数个数不正确时,不再执行后续步骤,直接向客户端返回一个错误。比如说,如果redisCommand结构体的arity属性的值为-3,那么用户输入的命令参数个数必须大于等于3个才行
- 检查客户端是否已经通过了身份验证,未通过身份验证的客户端只能执行AUTH命令,如果未通过身份验证的客户端试图执行除AUTH命令之外的其他命令, 那么服务器将向客户端返回一个错误
- 如果服务器打开了maxmemory功能,那么在执行命令之前,先检查服务器的内存占用情况,并在有需要时进行内存回收,从而使得接下来的命令可以顺利执行。如果内存回收失败,那么不再执行后续步骤,向客户端返回一个错误
- 如果服务器上一次执行BGSAVE命令时出错,并且服务器打开了stop-writes-on-bg-save-error功能,而且服务器即将要执行的命令是一个写命令,那么服务器将拒绝执行这个命令,并向客户端返回一个错误
- 如果客户端当前正在用SUBSCRIBE命令订阅频道,或者正在用PSUBSCRIBE命令订阅模式,那么服务器只会执行客户端发来的SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE、PUNSUBSCRIBE四个命令,其他别的命令都会被服务器拒绝
- 如果服务器正在进行数据载入,那么客户端发送的命令必须带有l标识(比如INFO、SHUTDOWN、PUBLISH,等等)才会被服务器执行,其他别的命令都会被服务器拒绝
- 如果服务器因为执行Lua脚本而超时并进入阻塞状态,那么服务器只会执行客户端发来的SHUTDOWN nosave命令和SCRIPTKILL命令,其他别的命令都会被服务器拒绝
- 如果客户端正在执行事务,那么服务器只会执行客户端发来的EXEC、DISCARD、MULTI、WATCH四个命令,其他命令都会被放进事务队列中
- 如果服务器打开了监视器功能,那么服务器会将要执行的命令和参数等信息发送给监视器
命令执行器(3):调用命令的实现函数
在面前的操作中,服务器已经将要被执行的命令保存到客户端状态的cmd属性中,并将命令的参数和参数个数分别保存到客户端状态argv属性和argc 属性,当服务器决定要执行命令时,它只要执行以下语句就可以了
// client 是指向客户端状态的指针 client->cmd->proc(client);
因为执行命令所需的实际参数都已经保存到客户端状态的argv属性里面了,所以命令的实现函数只需要一个指向客户端状态的指针作为参数即可。继续以之前的SET命令为例子,图1-6展示了客户端包含了命令实现、参数、参数个数的样子
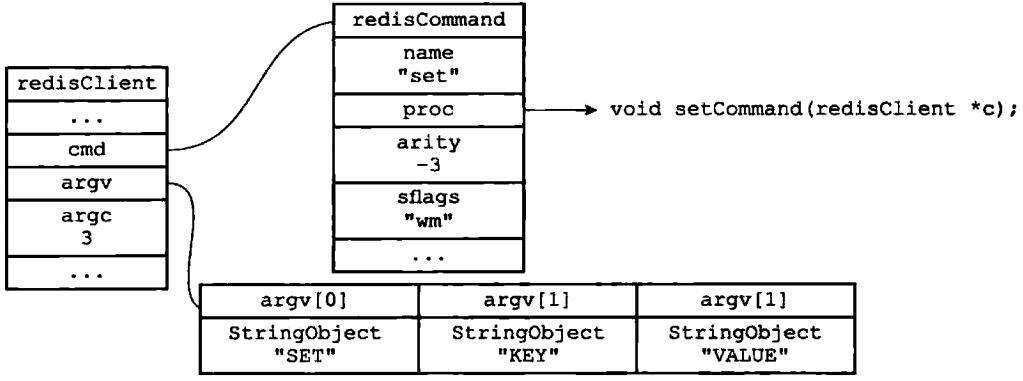
图1-6 客户端状态
对于这个例子来说, 执行语句:client->cmd->proc(client);等于执行语句:setCommand(client)
被调用的命令实现函数会执行指定的操作,并产生相应的命令回复,这些回复会被保存在客户端状态的输出缓冲中(buf属性和reply属性),之后实现函数还会为客户端的套接字关联命令回复处理器,这个处理器将命令回复返回给客户端
对于前面SET命令的例子来说,函数调用setCommand(client)将产生一个"+OK\r\n"回复,这个回复会保存到客户端状态的buf属性中,如图1-7所示
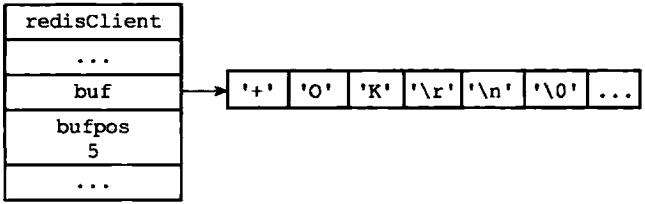
图1-7 保存了命令回复的客户端状态
命令执行器(4):执行后续工作
在执行完实现函数之后,服务器还需要执行一些后续工作:
- 如果服务器开启了慢查询日志功能,那么慢查询日志模块会检查是否需要为刚刚执行完的命令请求添加一条新的慢查询日志
- 根据刚刚执行命令所耗费的时长,更新被执行命令的redisCommand结构体的milliseconds属性,并将命令的redisCommand结构体的calls计数器的值加1
- 如果服务器开启AOF持久化功能,那么AOF持久化模块会将刚刚执行的命令请求写入到AOF缓冲区
- 如果有其他服务器正在复制当前这个服务器,那么服务器会将刚刚执行的命令传播给所有从服务器
当以上操作都执行完之后,服务器对当前命令的执行到此告一段落,之后服务器就可以继续从文件事件处理器中取出并处理下一个命令请求
将命令回复发送给客户端
前面说过,命令实现函数会将命令回复保存到客户端的输出缓冲,并为客户端的套接字关联命令回复处理器,当客户端套接字变为可写状态时,服务器就会执行命令回复处理器,将保存在客户端状态输出缓冲区的命令回复发送给客户端。当命令回复发送完毕之后,回复处理器会清空客户端状态的输出缓冲区,为处理下一个命令请求做好准备。以图1-7所示的客户端状态为例子,当客户端的套接字变为科协状态时,命令回复处理器会将协议格式的命令回复"+OK\r\n"发送给客户端
客户端接收并打印命令回复
当客户端接收到协议格式的命令回复之后,它会将这些回复转换成人们可以识别的可读模式,并打印给用于看,如图1-8所示

图1-8 客户端接收并打印命令回复的过程
继续之前SET命令为例子,当客户端接到服务器发来的"+OK\r\n"协议回复时,它会将这个回复转换成"OK\n",然后打印给用户看:
127.0.0.1:6379> SET KEY VALUE OK
以上就是Redis客户端和服务器执行命令请求的整个过程了
serverCron函数
Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并且保持服务器自身的良好运转。下面,我们将对serverCron函数执行的操作进行完整介绍,并介绍redisServer结构(服务器状态)中和serverCron有关的属性
更新服务器时间缓存
Redis服务器中有不少功能需要获取系统的当前时间,而每次获取系统的当前时间都需要执行一次系统调用,为了减少系统调用的次数,服务器状态中的unixtime属性和mstime属性被用作当前时间的缓存:
redis.h
struct redisServer {
……
//保存了秒级精度的系统当前Unix时间戳
time_t unixtime;
//保存了毫秒级精度的系统当前Unix时间戳
long long mstime;
……
};
因为serverCron函数默认会以100毫秒一次的频率更新unixtime属性和mstime属性,所以这两个属性记录的时间的精确度并不高:
- 服务器只会在打印日志、更新服务器的LRU时钟、决定是否执行持久化任务、计算服务器上线时间这类对时间精确度要求不高的功能上
- 对于为键设置过期时间、添加慢查询日志这种需要高精度时间的功能来说,服务器还是会再次执行系统调用,从而获得最准确的系统当前时间
更新LRU时钟
服务器中的lrulock属性保存了服务器的LRU时钟,这个属性和上面介绍的unixtime属性、mstime属性一样,都是服务器时间缓存的一种
redis.h
struct redisServer {
……
//默认每10秒更新一次时钟缓冲
//用于计算键的空转时长
unsigned lruclock:22;
……
};
每个Redis对象都会有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间:
redis.h
typedef struct redisObject {
……
unsigned lru:22;
……
} robj;
当服务器要计算一个数据库键的空转时间(也即是数据库键对应的值对象的空转时间),程序会用服务器的lruclock属性记录的时间减去对象的lru属性记录的时间,得出的计算结果就是这个对象的空转时间
127.0.0.1:6379> SET msg "hello world" OK #等待一段时间 127.0.0.1:6379> OBJECT IDLETIME msg (integer) 11 #等待一段时间 127.0.0.1:6379> OBJECT IDLETIME msg (integer) 26 #访问msg键的值 127.0.0.1:6379> GET msg "hello world" #键处于活跃状态,空转时间为1秒 127.0.0.1:6379> OBJECT IDLETIME msg (integer) 1
serverCron函数默认会以每10秒一次的频率更新lruclock属性的值,因为这个时钟不是实时,所以根据这个属性计算出来的LRU时间实际上只是一个模糊的估计值
lruclock时钟的当前值可以通过INFO server命令的lru_clock域查看:
127.0.0.1:6379> INFO server # Server …… lru_clock:11967088 ……
更新服务器每秒执行命令次数
serverCron函数中trackOperationsPerSecond函数会以每100毫秒一次的频率执行, 这个函数的功能是以抽样计算的方式,估算并记录服务器在最近一秒钟处理的命令请求数量,这个值可以通过INFO status命令的instantaneous_ops_per_sec域查看:
127.0.0.1:6379> INFO stats # Stats …… instantaneous_ops_per_sec:6 ……
上面的命令结果显示,在最近一秒钟内,服务器处理了大概六个命令。trackOperationsPerSecond函数和服务器状态中四个ops_sec开头的属性有关:
redis.h
struct redisServer {
……
//上次一进行抽样的时间
long long ops_sec_last_sample_time;
//上次一抽样时,服务器已执行命令的数量
long long ops_sec_last_sample_ops;
//REDIS_OPS_SEC_SAMPLES大小(默认值为16)的环形数组
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES];
//每次抽样后将值加1
//在值等于16时重置为0
//让ops_sec_samples数组构成一个换新数组
int ops_sec_idx;
……
};
trackOperationsPerSecond函数每次运行,都会根据ops_sec_last_sample_time记录的上一次抽样时间和服务器的当前时间,以及ops_sec_last_sample_time记录的上一次抽样已执行命令数量和服务器当前已执行命令数量,计算出两次trackOperationsPerSecond调用之间,服务器平均每一毫秒处理了多少个命令请求,然后将这个平均值乘以1000,这就得到了服务器在一秒钟内能处理多少个命令你请求的估计值,这个估计值会被作为一个新的数组项被放进ops_sec_samples环形数组里面
当客户端执行INFO命令时,服务器就会调用getOperationsPerSecond函数,根据ops_sec_samples环形数组中的抽样结果,计算出instantaneous_ops_per_sec属性的值,以下是getOperationsPerSecond函数的实现代码:
redis.c
long long getOperationsPerSecond(void) {
int j;
long long sum = 0;
//计算所有取样值的总和
for (j = 0; j < REDIS_OPS_SEC_SAMPLES; j++)
sum += server.ops_sec_samples[j];
//计算取样的平均值
return sum / REDIS_OPS_SEC_SAMPLES;
}
根据getOperationsPerSecond函数的定义可以看出,instantaneous_ops_per_sec属性的值是通过计算最近REDIS_OPS_SEC_SAMPLES次取样的平均值来计算得出的,它只是一个估算值
更新服务器内存峰值记录
服务器状态中的stat_peak_memory属性记录了服务器内存峰值大小:
redis.h
struct redisServer {
……
//已使用内存峰值
size_t stat_peak_memory;
……
};
每次serverCron函数执行时,程序都会查看服务器当前使用的内存数量,并与stat_peak_memory保存的数值进行比较,如果当前使用的内存数量比stat_peak_memory属性记录的值要大,那么程序就将当前使用的内存数量记录到stat_peak_memory属性里面
INFO memory命令的和used_memory_peak_human两个域分别以两种格式记录了服务器的内存峰值:
127.0.0.1:6379> INFO memory # Memory …… used_memory_human:848.87K used_memory_peak:870552 ……
处理SIGTERM信号
在启动服务器时,Redis会为服务器进程的SIGTERM信号关联处理器sigtermHandler函数,这个信号处理器负责在服务器接到SIGTERM信号时,打开服务器状态的shutdown_asap标识:
redis.c
//SIGTERM信号的处理器
static void sigtermHandler(int sig) {
REDIS_NOTUSED(sig);
//打印日志
redisLogFromHandler(REDIS_WARNING,"Received SIGTERM, scheduling shutdown...");
//打开关闭标识
server.shutdown_asap = 1;
}
每次serverCron函数运行时,程序都会对服务器状态的shutdown_asap属性进行检查,并根据属性的值决定是否关闭服务器:
redis.h
struct redisServer {
……
//关闭服务器的标识
//值为1时,关闭服务器
//值为0时,不做动作
int shutdown_asap;
……
};
以下代码展示了服务器在接到SIGTERM信号之后,关闭服务器并打印相关日志的过程:
[207 | signal handler] (1380450274) Received SIGTERM, scheduling shutdown... [207] 29 Sep 18:24:34.899 * Saving the final RDB snapshot before exiting. [207] 29 Sep 18:24:35.050 * DB saved on disk [207] 29 Sep 18:24:35.050 * Removing the pid file. [207] 29 Sep 18:24:35.150 # Redis is now ready to exit, bye bye...
从日志里面可以看到,服务器在关闭自身之前会进行RDB赤计划操作,这也是服务器拦截SIGTERM信号的原因,如果服务器一接到SIGTERM信号就立即关闭,那么它就没办法执行持久化操作了
管理客户端资源
serverCron函数每次执行都会调用clientsCron函数,clientsCron函数会对一定数量的客户端进行以下两个检查:
- 如果客户端与服务器之间的连接已经超时(很长一段时间里客户端和服务器都没有互动),那么程序会释放这个客户端
- 如果客户端在上一次执行命令请求后,输入缓冲区的大小超过一定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费过多内存
管理数据库资源
serverCron函数每次执行都会调用databasesCron函数,这个函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时,对字典进行收缩操作
执行被延迟的BGREWRITEAOF
在服务器执行BGSAVE命令的期间,如果客户端向服务器发来BGREWRITEAOF命令,那么服务器会将BGREWRITEAOF命令的执行延迟到BGSAVE命令执行完毕之后。服务器的aof_rewrite_scheduled标识记录了服务器是否延迟了BGREWRITEAOF命令
redis.h
struct redisServer {
……
//如果值为1,那么表示有BGREWRITEAOF命令被延迟了
int aof_rewrite_scheduled; /* Rewrite once BGSAVE terminates. */
……
};
每次serverCron函数执行时,函数都会检查BGSAVE命令或BGREWRITEAOF命令是否正在执行,如果这两个命令都没在执行,并且aof_rewrite_scheduled属性的值为1,那么服务器就会执行执行之前被推延的BGREWRITEAOF命令
检查持久化操作的运行状态
服务器状态使用rdb_child_pid属性和aof_child_pid属性记录执行BGSAVE命令和BGREWRITEAOF命令的子进程ID,这两个属性也可以用于检查BGSAVE命令或BGREWRITEAOF命令是否正在执行:
redis.h
struct redisServer {
……
//记录执行BGSAVE命令的子进程ID
//如果服务器没有执行BGSAVE
//那么这个属性的值为-1
pid_t aof_child_pid;
……
//记录执行BGREWRITEAOF命令的子进程ID
//如果服务器没有执行BGREWRITEAOF
//那么这个属性的值为-1
pid_t rdb_child_pid;
……
};
每次serverCron函数执行时,程序都会检查rdb_child_pid和aof_child_pid两个属性的值,只要其中一个属性的值不为-1,程序就会执行一次wait3函数,检查子进程是否有信号发来服务器进程:
- 如果有信号到达,那么表示新的RDB文件已经生成完毕(对于BGSAVE命令来说),或者AOF文件已重写完毕(对于BGREWRITEAOF命令来说),服务器需要进行相应命令的后续操作,比如用新的RDB文件替换现有的RDB文件,或者用重写后的AOF文件替换现有的AOF文件
- 如果没有信号到达,那么表示持久化操作未完成,程序不做动作
另一方面,如果rdb_child_pid和aof_child_pid两个属性的值都为-1,那么表示服务器没有在进行持久化操作,在这种情况下,程序执行以下三个检查:
- 查看是否有BGREWRITEAOF被延迟了,如果有的话,那么开始一次新的BGREWRITEAOF操作
- 检查服务器的自动保存条件是否已被满足,如果条件满足,并且服务器没有在执行其他持久化操作,那么服务器开始一次新的BGSAVE操作(因为条件1可能会引发一次BGREWRITEAOF,所以在这个检查中,程序会再次确认服务器是否已经在执行持久化操作了)
- 检查服务器设置的AOF重写条件是否满足,如果条件满足,并且服务器没有执行其他持久化操作,那么服务器将开始一次新的BGREWRITEAOF操作(因为条件1和条件2都可能会引发新的持久化操作,所以在这个检查中,程序会再次确认服务器是否已经在执行持久化操作了)
图1-9以流程图的方式展示了这个检查过程
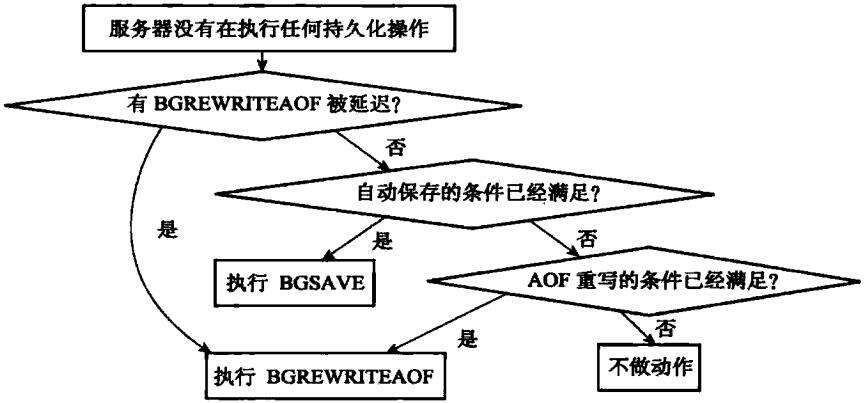
图1-9 判断是否需要执行持久化操作
将AOF缓冲区中的内容写入AOF文件
如果服务器开启了AOF持久化功能,并且AOF缓冲区里面还有待写入的数据,那么serverCron函数会调用相应的程序,将AOF缓冲区中的内容写入到AOF文件中
关闭异步客户端
在这一步,服务器会关闭那些输出缓冲区大小超出限制的客户端
增加cronloops计数器的值
服务器状态的cronloops属性记录了serverCron函数执行的次数:
redis.h
struct redisServer {
……
//serverCron函数的运行次数计数器
//serverCron函数每执行一次,这个属性的值就加1
int cronloops;
……
};
cronloops属性目前在服务器中唯一的作用,就是在复制模块中实现“每执行serverCron函数N次就执行一次指定代码”的功能
初始化服务器
一个Redis服务器从启动到能够接受客户端的命令请求,需要经过一系列的初始化和设置过程,比如初始化服务器状态、接受用户指定的服务器配置、创建相应的数据结构和网络连接等等,本节接下来的内容将对服务器的整个初始化过程做详细介绍
初始化服务器状态结构
初始化服务器的第一步就是创建一个struct redisServer类型的实例变量server作为服务器的状态,并为结构中的各个属性设置默认值。初始化server变量的工作由redis.c/initServerConfig函数完成,以下是这个函最开头的一部分代码:
redis.c
void initServerConfig(void){
// 设置服务器的运行id
getRandomHexChars(server.runid,REDIS_RUN_ID_SIZE);
// 为运行id加上结尾字符
server.runid[REDIS_RUN_ID_SIZE] = '\0';
// 设置默认配置文件路径
server.configfile = NULL;
// 设置默认服务器频率
server.hz = REDIS_DEFAULT_HZ;
// 设置服务器的运行架构
server.arch_bits = (sizeof(long) == 8) ? 64 : 32;
// 设置默认服务器端口号
server.port = REDIS_SERVERPORT;
...
}
以下是initServerConfig函数完成的主要工作:
- 设置服务器的运行ID
- 设置服务器的默认运行频率
- 设置服务器的默认配置文件路径
- 设置服务器的运行架构
- 设置服务器的默认端口号
- 设置服务器的默认RDB持久化条件和AOF持久化条件
- 初始化服务器的LRU时钟
- 创建命令表
initServerConfig函数设置的服务器状态属性基本都是一些整数、浮点数、或者字符串属性,除了命令表外,initServerConfig函数没有创建服务器状态的其他数据结构,数据库、慢查询日志、Lua环境、共享对象这些数据结构在之后的步骤才会被创建出来。当initServerConfig函数执行完毕之后,服务器就可以进入初始化的第二个阶段——载入配置选项
载入配置选项
在启动服务器时,用户可以通过给定配置参数或指定配置文件来修改服务器的默认配置。举个栗子,如果我们在终端输入:
# redis-server --port 10086
那么我们就通过给定配置参数的方式,修改了服务器的运行端口号。另外,如果我们在终端中输入:
# redis-server redis.conf
那么我们就通过指定配置文件的方式修改了服务器的数据库数量,以及RDB持久化模块的压缩功能。服务器在用initServerConfig函数初始化完server变量之后,就会开始载入用户给定的配置参数和配置文件,并根据用户设定的配置,对server变量相关属性的值进行修改。例如,在初始化server变量时,程序会为决定服务器端口号的port属性设置默认值
redis.c
void initServerConfig() {
……
//默认值为6379
server.port = REDIS_SERVERPORT;
……
}
不过,如果用户在启动服务器时配置项port指定了新值10086,那么server.port属性的值就会更新为10086
在初始化server变量时,程序会为决定数据库数量的dbnum属性设置默认值:
redis.c
void initServerConfig() {
……
//默认值为16
server.dbnum = REDIS_DEFAULT_DBNUM;
……
}
不过,如果用户在启动服务器时为选项databases设置了值32,那么server.dbnum属性的值会被更新为32,这将使得服务器的数据库数量从默认的16个变量用户指定的32个
其他配置项相关的服务器状态属性的情况与上面例举的port属性和dbnum属性一样:
- 如果用户为这些属性的相应选项指定了新的值,那么服务器就使用用户指定的值来更新相应的属性
- 如果用户没有为属性的相关选项设置新值,那么服务器就沿用为initServerConfig函数设定好的默认值
初始化服务器数据库结构
在之前执行initServerConfig函数初始化server状态时,程序只创建了命令表一个数据结构,不过除了命令表之外,服务器状态还包含其他数据结构,比如:
- server.clients链表,这个链表记录了所有与服务器相连的客户端的状态结构,链表的每个节点都包含了一个redisClient结构实例
- server.db数组,数组中包含了服务器的所有数据库
- 用于保存频道订阅信息的server.pubsub_channels字典,以及用于保存模式订阅信息的server.pubsub_patterns链表
- 用于执行Lua脚本的Lua环境server.lua
- 用于保存慢查询日志的server.slowlog属性
当初始化服务器进行到这一步,服务器将调用initServer函数,为以上提到的数据结构分配内存,并在有需要时,为这些数据结构设置或关联初始化值。服务器到现在才初始化数据结构的原因在于,服务器必须先载入用户指定的配置选项,然后才能正确地对数据结构进行初始化。如果在执行initServerConfig函数时就对数据结构进行初始化,那么一旦用户通过配置项修改了和数据结构相关的服务器状态属性,服务器就要重新调整和修改已创建的数据结构。伪劣避免出现这种麻烦的情况,服务器选择了将server状态的初始化分为两步进行,initServerConfig函数主要负责初始化一般属性,而initServer函数主要负责初始化数据结构
除了初始化数据结构之外,initServer还进行了一些非常重要的操作,其中包括:
- 为服务器设置进程信号处理器
- 创建共享对象:这些对象包含Redis服务器经常用到的一些值,比如包含"OK"回复的字符串对象,包含"ERR"回复的字符串对象,包含整数1到10000的字符串对象等等,服务器通过重用这些共享对象来避免反复创建相同的对象
- 打开服务器的监听端口,并为监听套接字关联连接应答事件处理器,等待服务器正式运行时接受客户端的连接
- 为serverCron函数创建时间事件,等待服务器正式运行时执行serverCron函数
- 如果AOF持久化功能已经打开,那么打开现有的AOF文件,如果AOF文件不存在,那么创建并打开一个新的AOF文件,为AOF写入做好准备
- 初始化服务器的后台I/O模块(bio),为将来的I/O操作做好准备
还原数据库状态
在完成了对服务器状态server变量的初始化之后,服务器需要载入RDB文件或AOF文件,并根据文件记录的内容来还原服务器的数据库状态
根据服务器是否启用AOF持久化功能,服务器载入数据时所使用的目标文件会有所不同:
- 如果服务器启用了AOF持久化功能,那么服务器使用AOF文件来还原数据库状态
- 相反地,如果服务器没有启用AOF持久化功能,那么服务器使用RDB文件来还原数据库状态
当服务器完成数据库状态还原工作之后,服务器将在日志中打印出载入文件并还原数据库状态所耗费的时长:
[5244] 21 Nov 22:43:49.084 * DB loaded from disk: 0.068 seconds
执行事件循环
在初始化最后一步,服务器将打印出日志:
[5244] 21 Nov 22:43:49.084 * The server is now ready to accept connections on port 6379
并开始执行服务器的事件循环(loop)。至此,服务器的初始化工作圆满完成,服务器现在开始可以接受客户端的连接请求,并处理客户端发来的命令请求了
本文标题为:Redis实现之服务器


基础教程推荐








- Mysql查看死锁与解除死锁的深入讲解 2024-02-14
- 如何保障mysql和redis之间的数据一致性 2024-04-25
- 浅谈数据库优化方案 2024-02-16
- Redis GEORADIUS命令 2024-04-06
- MySQL索引优化之适合构建索引的几种情况详解 2023-12-29
- Redis配置项汇总 2024-04-04
- SQL Server之SELECT INTO 和 INSERT INTO SELECT案例详解 2024-02-13
- mysql服务启动却连接不上的解决方法 2023-12-08
- mysql时间字段默认设置为当前时间实例代码 2022-08-31
- 详解Redis连接命令使用方法 2024-03-23








