MapReduce是一种用于处理大规模数据集的并行编程模型,其特点高效性和可扩展性,在本文中,我们将深入了解MapReduce,并使用Java编写一个简单的MapReduce程序,需要的朋友可以参考下
一个Maprduce程序主要包括三部分:Mapper类、Reducer类、执行类。
Maven项目下所需依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>数据类型
- Text: 一种可变长度的字节数组,用于表示文本数据。相当于Java中的String。
- LongWritable、IntWritable、FloatWritable、DoubleWritable: 分别用于表示长整型、整型、浮点型和双精度浮点型数据。相当于Java中的long、int、float和double。
- BooleanWritable: 用于表示布尔类型数据。相当于Java中的boolean。
- NullWritable: 用于表示空值,通常用于表示Map任务的输出中间结果数据中的值为空。相当于Java中的null。
- ArrayWritable: 用于表示数组类型数据。相当于Java中的数组。
- MapWritable: 一种可序列化的Map数据结构,可以作为Map任务的输出(中间结果数据)或Reduce任务的输入。相当于Java中的Map<>。
- WritableComparable: 一种可序列化的、可比较的数据类型接口,可以作为Map任务或Reduce任务的输入输出数据类型。
一、Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//如果当前数据不为空
if (value!=null){
//获取每一行的数据
String line = value.toString();
//将一行数据根据空格分开
// String[] words = line.split(" ");
String[] words = StringUtils.split(line,' ');//hadoop的StringUtils.split方法对大数据来说比Java自带的拥有更好的性能
//输出键值对
for (String word : words) {
context.write(new Text(word),new LongWritable(1));
}
}
}
}二、Reducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//累加单词的数量
long sum = 0;
//遍历单词计数数组,将值累加到sum中
for (LongWritable value : values) {
sum += value.get();
}
//输出每次最终的计数结果
context.write(key,new LongWritable(sum));
}
}三、执行类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountRunner extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new WordCountRunner(),args);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountRunner.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径
//读取maven项目下resources目录的文档
String path = getClass().getResource("/words.txt").getPath();
FileInputFormat.setInputPaths(job,path);
//设置结果数据存放路径,将命令行的第二个参数作为数据的输出路径
//输出目录必须不存在!!!
FileOutputFormat.setOutputPath(job,new Path("./output"));
return job.waitForCompletion(true) ? 0 : 1;
}
}程序执行结果
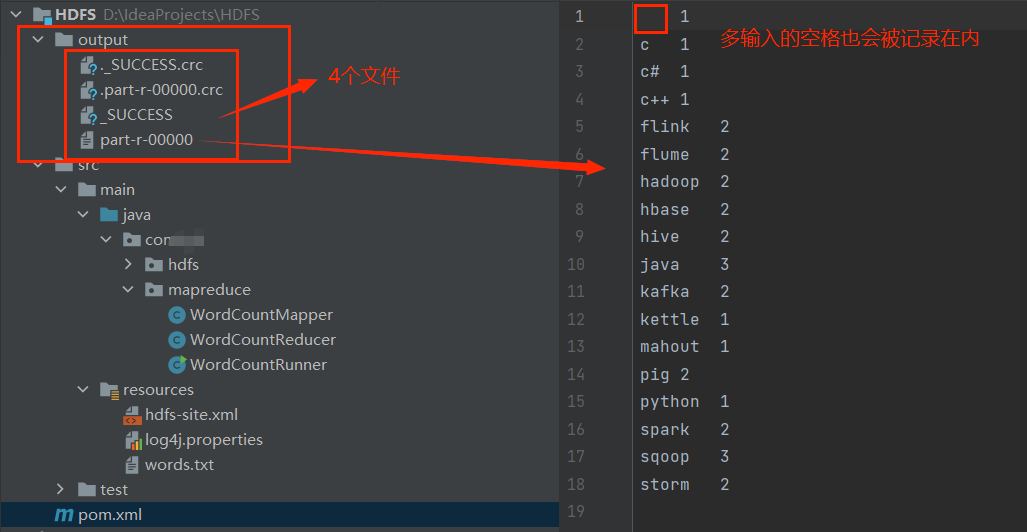
- .part-r-00000.crc: 是Reduce任务输出结果文件的校验文件,用于校验Reduce任务输出结果文件的完整性和正确性。该文件由Hadoop框架自动生成,不需要手动创建,其内容是Reduce任务输出结果文件的校验和信息。
- ._SUCCESS.crc: 是表示任务执行成功的标志文件的校验文件,用于校验标志文件的完整性和正确性。该文件由Hadoop框架自动生成,其内容是标志文件的校验和信息。
- _SUCCESS: 表示任务执行成功的标志文件,文件内容为空。
- part-r-00000: 表示Reduce任务的输出结果文件,其中“00000”表示该文件是第一个Reduce任务的输出结果文件,如果有多个Reduce任务,则会生成多个该类型的文件,文件内容为每个单词出现的次数。
到此这篇关于Java编写Mapreduce程序过程浅析的文章就介绍到这了,更多相关Java编写Mapreduce内容请搜索编程学习网以前的文章希望大家以后多多支持编程学习网!
沃梦达教程
本文标题为:Java编写Mapreduce程序过程浅析


基础教程推荐








猜你喜欢
- springboot下使用shiro自定义filter的个人经验分享 2024-02-27
- JavaWeb 实现验证码功能(demo) 2024-04-14
- 运用El表达式截取字符串/获取list的长度实例 2023-08-01
- 是否适合从javabean类更新数据库? 2023-11-04
- Java+mysql实现学籍管理系统 2023-03-16
- 深入理解约瑟夫环的数学优化方法 2024-03-07
- Java编写实现窗体程序显示日历 2023-01-02
- 使用Java和WebSocket实现网页聊天室实例代码 2024-02-25
- Java中EnvironmentAware 接口的作用 2023-01-23
- JSP 动态树的实现 2023-12-17








