这篇文章主要介绍了如何重写hashcode和equals方法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教
如何重写hashcode和equals方法
我们都知道,要比较两个对象是否相等时需要调用对象的equals()方法,即判断对象引用所指向的对象地址是否相等,对象地址相等时,那么与对象相关的对象句柄、对象头、对象实例数据、对象类型数据等也是完全一致的,所以我们可以通过比较对象的地址来判断是否相等。
Object源码理解
对象在不重写的情况下使用的是Object的equals方法和hashcode方法,从Object类的源码我们知道,默认的equals 判断的是两个对象的引用指向的是不是同一个对象;而hashcode也是根据对象地址生成一个整数数值;
另外我们可以看到Object的hashcode()方法的修饰符为native,表明该方法是否操作系统实现,java调用操作系统底层代码获取哈希值。
public class Object {
public native int hashCode();
/**
* Indicates whether some other object is "equal to" this one.
* <p>
* The {@code equals} method implements an equivalence relation
* on non-null object references:
* <ul>
* <li>It is <i>reflexive</i>: for any non-null reference value
* {@code x}, {@code x.equals(x)} should return
* {@code true}.
* <li>It is <i>symmetric</i>: for any non-null reference values
* {@code x} and {@code y}, {@code x.equals(y)}
* should return {@code true} if and only if
* {@code y.equals(x)} returns {@code true}.
* <li>It is <i>transitive</i>: for any non-null reference values
* {@code x}, {@code y}, and {@code z}, if
* {@code x.equals(y)} returns {@code true} and
* {@code y.equals(z)} returns {@code true}, then
* {@code x.equals(z)} should return {@code true}.
* <li>It is <i>consistent</i>: for any non-null reference values
* {@code x} and {@code y}, multiple invocations of
* {@code x.equals(y)} consistently return {@code true}
* or consistently return {@code false}, provided no
* information used in {@code equals} comparisons on the
* objects is modified.
* <li>For any non-null reference value {@code x},
* {@code x.equals(null)} should return {@code false}.
* </ul>
* <p>
* The {@code equals} method for class {@code Object} implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values {@code x} and
* {@code y}, this method returns {@code true} if and only
* if {@code x} and {@code y} refer to the same object
* ({@code x == y} has the value {@code true}).
* <p>
* Note that it is generally necessary to override the {@code hashCode}
* method whenever this method is overridden, so as to maintain the
* general contract for the {@code hashCode} method, which states
* that equal objects must have equal hash codes.
*
* @param obj the reference object with which to compare.
* @return {@code true} if this object is the same as the obj
* argument; {@code false} otherwise.
* @see #hashCode()
* @see java.util.HashMap
*/
public boolean equals(Object obj) {
return (this == obj);
}
}需要重写equals()的场景
假设现在有很多学生对象,默认情况下,要判断多个学生对象是否相等,需要根据地址判断,若对象地址相等,那么对象的实例数据一定是一样的,但现在我们规定:当学生的姓名、年龄、性别相等时,认为学生对象是相等的,不一定需要对象地址完全相同,例如学生A对象所在地址为100,学生A的个人信息为(姓名:A,性别:女,年龄:18,住址:北京软件路999号,体重:48),学生A对象所在地址为388,学生A的个人信息为(姓名:A,性别:女,年龄:18,住址:广州暴富路888号,体重:55),这时候如果不重写Object的equals方法,那么返回的一定是false不相等,这个时候就需要我们根据自己的需求重写equals()方法了。
package jianlejun.study;
public class Student {
private String name;// 姓名
private String sex;// 性别
private String age;// 年龄
private float weight;// 体重
private String addr;// 地址
// 重写hashcode方法
@Override
public int hashCode() {
int result = name.hashCode();
result = 17 * result + sex.hashCode();
result = 17 * result + age.hashCode();
return result;
}
// 重写equals方法
@Override
public boolean equals(Object obj) {
if(!(obj instanceof Student)) {
// instanceof 已经处理了obj = null的情况
return false;
}
Student stuObj = (Student) obj;
// 地址相等
if (this == stuObj) {
return true;
}
// 如果两个对象姓名、年龄、性别相等,我们认为两个对象相等
if (stuObj.name.equals(this.name) && stuObj.sex.equals(this.sex) && stuObj.age.equals(this.age)) {
return true;
} else {
return false;
}
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public float getWeight() {
return weight;
}
public void setWeight(float weight) {
this.weight = weight;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
}现在我们写个例子测试下结果:
public static void main(String[] args) {
Student s1 =new Student();
s1.setAddr("1111");
s1.setAge("20");
s1.setName("allan");
s1.setSex("male");
s1.setWeight(60f);
Student s2 =new Student();
s2.setAddr("222");
s2.setAge("20");
s2.setName("allan");
s2.setSex("male");
s2.setWeight(70f);
if(s1.equals(s2)) {
System.out.println("s1==s2");
}else {
System.out.println("s1 != s2");
}
}
在重写了student的equals方法后,这里会输出s1 == s2,实现了我们的需求,如果没有重写equals方法,那么上段代码必定输出s1!=s2。
通过上面的例子,你是不是会想,不是说要同时重写Object的equals方法和hashcode方法吗?那上面的例子怎么才只用到equals方法呢,hashcode方法没有体现出来,不要着急,我们往下看。
需要重写hashcode()的场景
以上面例子为基础,即student1和student2在重写equals方法后被认为是相等的。
在两个对象equals的情况下进行把他们分别放入Map和Set中
在上面的代码基础上追加如下代码:
Set set = new HashSet();
set.add(s1);
set.add(s2);
System.out.println(set);如果没有重写Object的hashcode()方法(即去掉上面student类中hashcode方法块),这里会输出
[jianlejun.study.Student@7852e922, jianlejun.study.Student@4e25154f]
说明该Set容器类有2个元素。.........等等,为什么会有2个元素????刚才经过测试,s1不是已经等于s2了吗,那按照Set容器的特性会有一个去重操作,那为什么现在会有2个元素。这就涉及到Set的底层实现问题了,这里简单介绍下就是HashSet的底层是通过HashMap实现的,最终比较set容器内元素是否相等是通过比较对象的hashcode来判断的。现在你可以试试吧刚才注释掉的hashcode方法弄回去,然后重新运行,看是不是很神奇的就只输出一个元素了
@Override
public int hashCode() {
int result = name.hashCode();
result = 17 * result + sex.hashCode();
result = 17 * result + age.hashCode();
return result;
}或许你会有一个疑问?hashcode里的代码该怎么理解?该如何写?其实有个相对固定的写法,先整理出你判断对象相等的属性,然后取一个尽可能小的正整数(尽可能小时怕最终得到的结果超出了整型int的取数范围),这里我取了17,(好像在JDK源码中哪里看过用的是17),然后计算17*属性的hashcode+其他属性的hashcode,重复步骤。
重写hashcode方法后输出的结果为:
[jianlejun.study.Student@43c2ce69]
同理,可以测试下放入HashMap中,key为<s1,s1>,<s2,s2>,Map也把两个同样的对象当成了不同的Key(Map的Key是不允许重复的,相同Key会覆盖)那么没有重写的情况下map中也会有2个元素,重写的情况会最后put进的元素会覆盖前面的value
Map m = new HashMap();
m.put(s1, s1);
m.put(s2, s2);
System.out.println(m);
System.out.println(((Student)m.get(s1)).getAddr());
输出结果:
{jianlejun.study.Student@43c2ce69=jianlejun.study.Student@43c2ce69}
222可以看到最终输出的地址信息为222,222是s2成员变量addr的值,很明天,s2已经替换了map中key为s1的value值,最终的结果是map<s1,s2>。即key为s1value为s2.
原理分析
因为我们没有重写父类(Object)的hashcode方法,Object的hashcode方法会根据两个对象的地址生成对相应的hashcode;
s1和s2是分别new出来的,那么他们的地址肯定是不一样的,自然hashcode值也会不一样。
Set区别对象是不是唯一的标准是,两个对象hashcode是不是一样,再判定两个对象是否equals;
Map 是先根据Key值的hashcode分配和获取对象保存数组下标的,然后再根据equals区分唯一值(详见下面的map分析)
补充HashMap知识
- hashMap组成结构:hashMap是由数组和链表组成;
- hashMap的存储:一个对象存储到hashMap中的位置是由其key 的hashcode值决定的;查hashMap查找key: 找key的时候hashMap会先根据key值的hashcode经过取余算法定位其所在数组的位置,再根据key的equals方法匹配相同key值获取对应相应的对象;
案例:
(1)hashmap存储
存值规则:把Key的hashCode 与HashMap的容量 取余得出该Key存储在数组所在位置的下标(源码定位Key存储在数组的哪个位置是以hashCode & (HashMap容量-1)算法得出)这里为方便理解使用此方式;
//为了演示方便定义一个容量大小为3的hashMap(其默认为16)
HashMap map=newHashMap(3);
map.put("a",1); 得到key 为“a” 的hashcode 值为97然后根据 该值和hashMap 容量取余97%3得到存储位到数组下标为1;
map.put("b",2); 得到key 为“b” 的hashcode 值为98,98%3到存储位到数组下标为2;
map.put("c",3); 得到key 为“c” 的hashcode 值为99,99%3到存储位到数组下标为0;
map.put("d",4); 得到key 为“d” 的hashcode 值为100,100%3到存储位到数组下标为1;
map.put("e",5); 得到key 为“e” 的hashcode 值为101,101%3到存储位到数组下标为2;
map.put("f",6); 得到key 为“f” 的hashcode 值为102,102%3到存储位到数组下标为0;
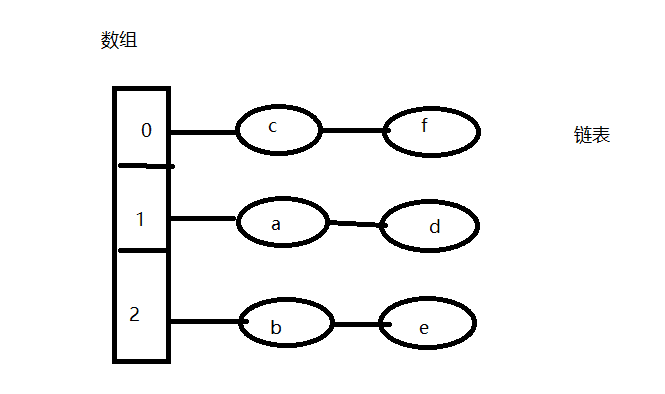
(2)hashmap的查找key
得到key在数组中的位置:根据上图,当我们获取key 为“a”的对象时,那么我们首先获得 key的hashcode97%3得到存储位到数组下标为1;
匹配得到对应key值对象:得到数组下表为1的数据“a”和“c”对象, 然后再根据 key.equals()来匹配获取对应key的数据对象;
hashcode 对于HashMapde:如果没有hashcode 就意味着HashMap存储的时候是没有规律可寻的,那么每当我们map.get()方法的时候,就要把map里面的对象一一拿出来进行equals匹配,这样效率是不是会超级慢;
hashcode方法文档说明
在equals方法没被修改的前提下,多次调用同一对象的hashcode方法返回的值必须是相同的整数;
如果两个对象互相equals,那么这两个对象的hashcode值必须相等;
为不同对象生成不同的hashcode可以提升哈希表的性能;
重写hashCode和equals方法的一些思考
经常能看到重写equals方法就需要重写hashCode方法的说法,这点也很好理解,假如重写equals使得两个对象通过equals判断为真 ,但是如果hashCode计算出来的值如果不一样,就会发生矛盾,就是明明两个对象是一样的,但是却会被映射到不同位置,这样子的话,hashMap或者hashSet之类的哈希结构就会存储多个相同的对象。
还可以通过一个例子理解
Map<String,Value> map1 = new HashMap<String,Value>();
String s1 = new String("key");
String s2 = new String("key");
Value value = new Value(2);
map1.put(s1, value);
System.out.println("s1.equals(s2):"+s1.equals(s2));
System.out.println("map1.get(s1):"+map1.get(s1));
System.out.println("map1.get(s2):"+map1.get(s2));
Map<Key,Value> map2 = new HashMap<Key,Value>();
Key k1 = new Key("A");
Key k2 = new Key("A");
map2.put(k1, value);
System.out.println("k1.equals(k2):"+k1.equals(k2));
System.out.println("map2.get(k1):"+map2.get(k1));
System.out.println("map2.get(k2):"+map2.get(k2));Key和Value的类定义如下
static class Key{
private String k;
public Key(String key){
this.k=key;
}
//如果不重写hashCode,只重写了equals,会造成相同值被放入不同的桶中
// @Override
// public int hashCode() {
// return k.hashCode();
// }
@Override
public boolean equals(Object obj) {
if(obj instanceof Key){
Key key=(Key)obj;
return k.equals(key.k);
}
return false;
}
}
static class Value{
private int v;
public Value(int v){
this.v=v;
}
@Override
public String toString() {
return "类Value的值-->"+v;
}
}
输出结果如下

可以看出,如果重写了equals但不重写hashCode的话,会出现相同的对象会被map判断成不同对象,导致可以重复插入多个相同对象。
除此之外,还会思考如果重写hashCode但不重写equals方法的情况下,又会造成什么问题,因此用以下例子说明
Map<Integer, Integer> map3 =new HashMap();
while (true){
boolean flag = false;
for (int i = 0; i < 1000; i++) {
if(!map3.containsKey(i)){
map3.put(i, i);
flag = true;
}
}
if (flag == false) {
break;
}
System.out.println("map3的容量" + map3.size());
}
Map<Key2, Integer> map4 =new HashMap();
while (true){
boolean flag = false;
for (int i = 0; i < 1000; i++) {
if(!map4.containsKey(new Key2(i))){
map4.put(new Key2(i), i);
flag = true;
}
}
if (flag == false) {
break;
}
System.out.println("map4的容量" + map4.size());
}
Key2的类定义如下
static class Key2{
Integer id;
Key2(Integer id) {
this.id = id;
}
@Override
public int hashCode() {
return id.hashCode();
}
//不重写equals就会导致一直认为没有相同的值,就会一直插入。
// @Override
// public boolean equals(Object obj) {
// if(obj instanceof Key2){
// Key2 key2 =(Key2)obj;
// return id.equals(key2.id);
// }
// return false;
// }
}
结果如下
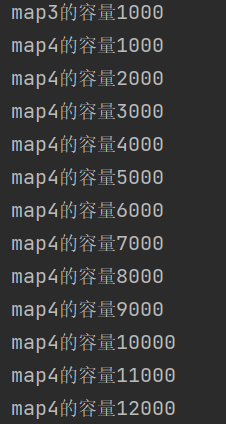
从图中结果可以看出,map4一直在添加数据,说明map一直认为没有相同的key对象,因此对于同一个i,不重写的equals永远不会判断相同,所以会一直插入。因此hashCode和equals必须全部重写,任何一个不重写都会发生错误。
到这里也还会思考,String和Integer的和hashCode和equals是怎么计算的
Integer的hashCode计算如下
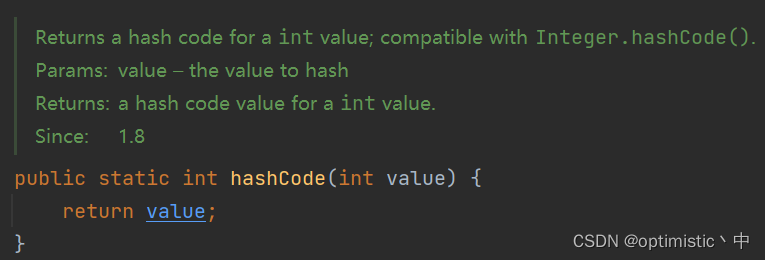
可以看出是直接返回原始值
String的hashCode计算如下
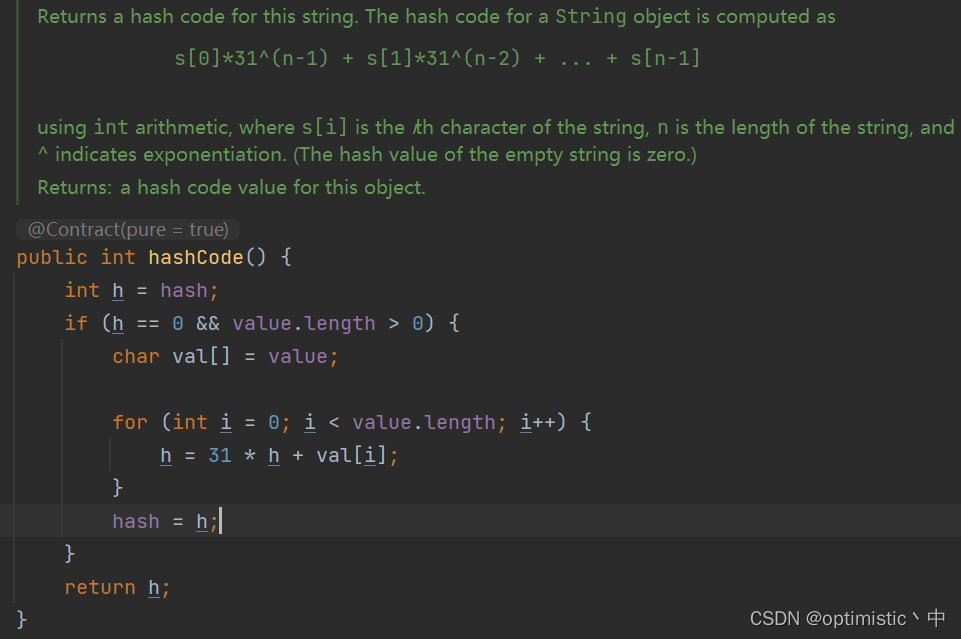
可以由注释看出来,计算的结果就是s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1],就比如字符串“abc”,a的ascll码是97,b是98,c是99,因此该字符串的hashCode值就是(97 *31 + 98)*31 + 99,这里引出一点思考:为什么用31呢?,查阅资料得知因为31是一个质数,可以使得减少哈希算法的冲突概率,同时31的二进制数是11111,因此31 *i就等于(i << 5) - i,可以优化运算。
Integer的equals计算如下
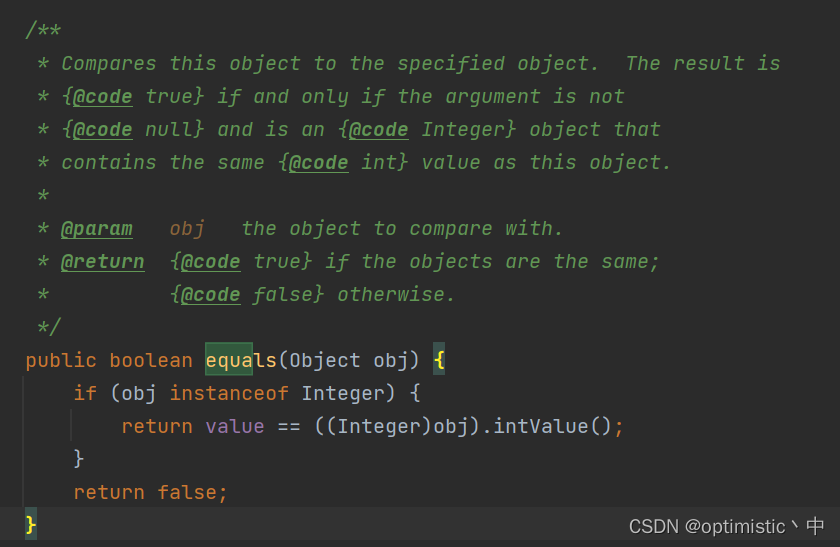
就是说明,只需要使用instanceof判断传入对象是否是Integer的实例或者子类,是就强转成Integer类,然后判断值是否相等
String的equals计算如下
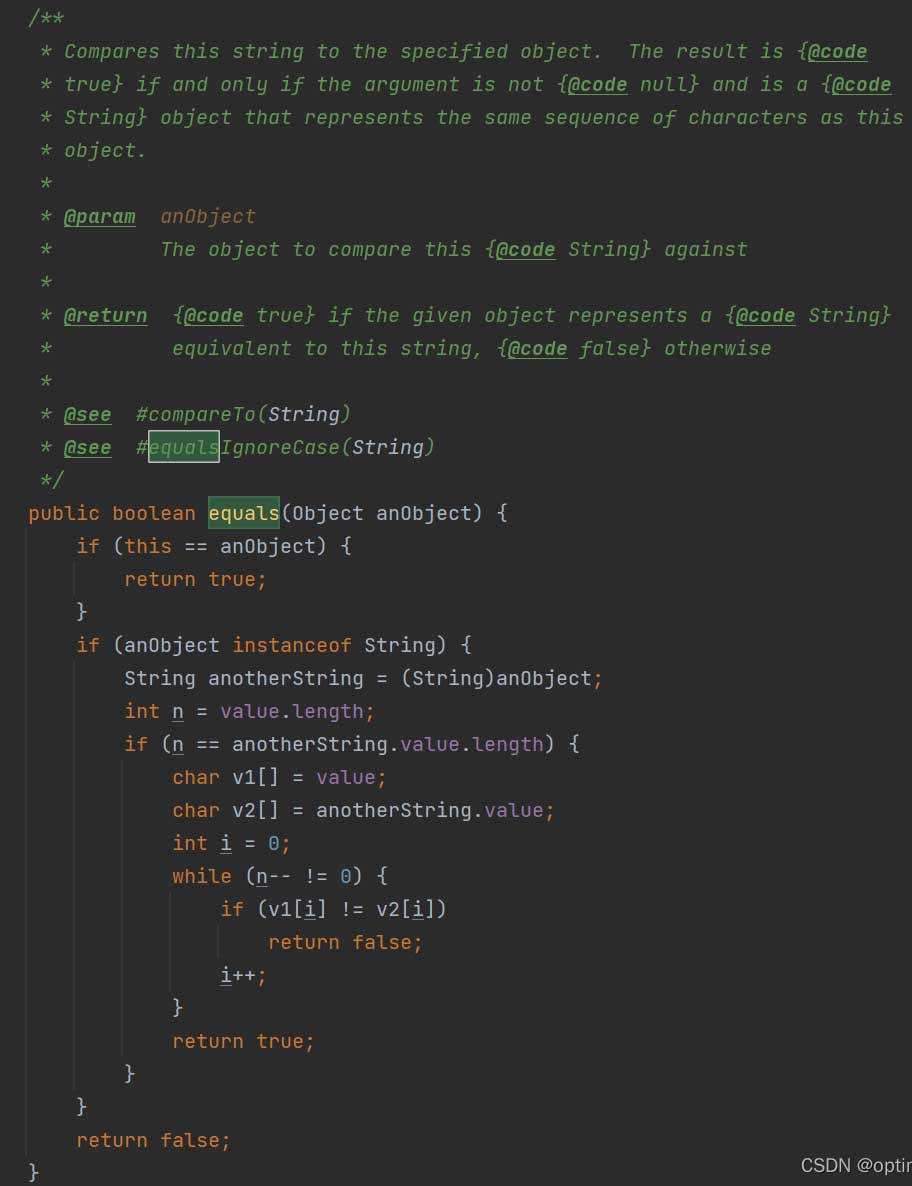
这里首先用“==”比较了equals两边对象,如果一样直接返回true,然后就是用instanceof判断是否是String实例或者子类,如果是就强转,然后再根据数组长度判断是否相同,如果相同就遍历数组每个元素,都相同就返回true,其他情况都返回false。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程学习网。
本文标题为:如何重写hashcode和equals方法


基础教程推荐








- 运用El表达式截取字符串/获取list的长度实例 2023-08-01
- springboot下使用shiro自定义filter的个人经验分享 2024-02-27
- JavaWeb 实现验证码功能(demo) 2024-04-14
- JSP 动态树的实现 2023-12-17
- Java中EnvironmentAware 接口的作用 2023-01-23
- Java编写实现窗体程序显示日历 2023-01-02
- Java+mysql实现学籍管理系统 2023-03-16
- 深入理解约瑟夫环的数学优化方法 2024-03-07
- 是否适合从javabean类更新数据库? 2023-11-04
- 使用Java和WebSocket实现网页聊天室实例代码 2024-02-25








