这篇文章主要介绍了结合线程池实现apache kafka消费者组的误区及解决方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
一个错误:多线程使用单一消费者
下图显现了一种错误的使用KafkaConsumer的方法
- 创建多个线程用来消费kafka数据
- 多线程使用同一个KafkaConsumer对象
- 在单线程中使用这个KafkaConsumer对象,完成数据拉取、处理、提交偏移量。
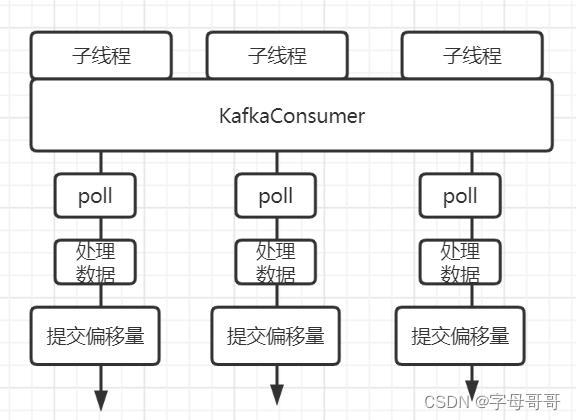
这种方式之所以错误的原因是:KafkaConsumer是线程不安全的,可能出现把同一批数据既给线程A处理,也交给线程B处理重复消费的问题。
一个误区:多线程就是消费者组
下图中体现的是一种正常的KafkaConsumer使用方式
- 使用一个KafkaConsumer拉取数据
- 拉取数据后将一个批次的数据交给一个线程去处理
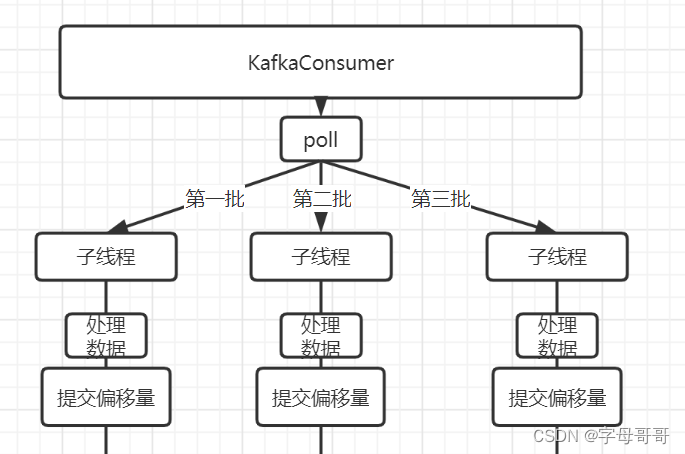
这个处理方式不是错误,但是他只是一个消费者在消费kafka消息队列中的数据,不是消费者组的方式消费数据。无法充分利用kafka分区提升消息处理的吞吐量。
常规正确做法:使用线程池实现消费者组
下面的方法是常规的正确实现方式
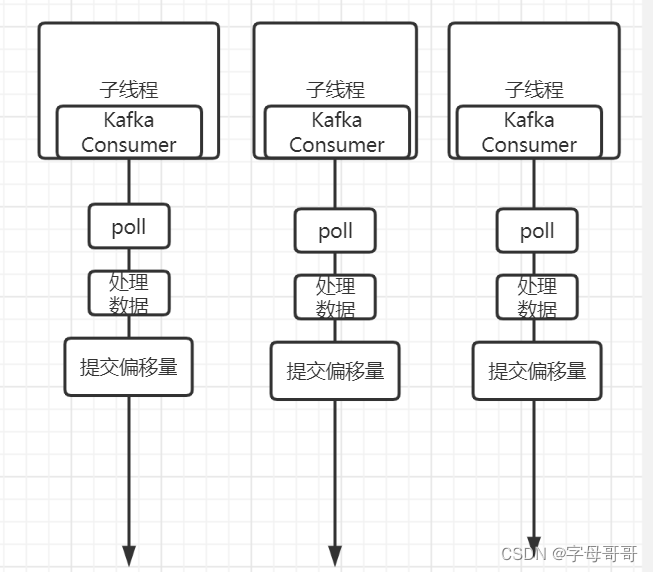
- 因为KafkaConsumer是线程不安全的,所以不能跨线程使用KafkaConsumer
- 每个线程持有一个KafkaConsumer对象
- 多个线程的实现可以使用线程池,线程池的线程数量等于消费者组内消费者的数量
public class MyConsumerGroup {
public void groupConsumer(){
ExecutorService executorService = Executors.newFixedThreadPool(6);
for (int i = 0; i < 6; i++) {
MyConsumer myConsumer = new MyConsumer();
executorService.execute(myConsumer);
}
}
}MyConsumer方法需要实现Runnable接口,并在run方法中调用MyConsumer#pollData。MyConsumer的代码参考本专栏的《消费者Java实现》( 集成apache kafka-clients实现数据消费者)
@Override
public void run() {
MyConsumer myConsumer = new MyConsumer();
myConsumer.pollData();
}到此这篇关于结合线程池实现apache kafka消费者组的文章就介绍到这了,更多相关apache kafka消费者组内容请搜索编程学习网以前的文章希望大家以后多多支持编程学习网!
沃梦达教程
本文标题为:结合线程池实现apache kafka消费者组的误区及解决方法


基础教程推荐








猜你喜欢
- 使用Java和WebSocket实现网页聊天室实例代码 2024-02-25
- JSP 动态树的实现 2023-12-17
- 是否适合从javabean类更新数据库? 2023-11-04
- Java编写实现窗体程序显示日历 2023-01-02
- Java中EnvironmentAware 接口的作用 2023-01-23
- JavaWeb 实现验证码功能(demo) 2024-04-14
- Java+mysql实现学籍管理系统 2023-03-16
- springboot下使用shiro自定义filter的个人经验分享 2024-02-27
- 运用El表达式截取字符串/获取list的长度实例 2023-08-01
- 深入理解约瑟夫环的数学优化方法 2024-03-07








