这篇文章主要介绍了Java如何自定义线程池中队列,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下
背景
业务交互的过程中涉及到了很多关于SFTP下载的问题,因此在代码中定义了一些线程池,使用中发现了一些问题,
代码类似如下所示:
public class ExecutorTest {
private static ExecutorService es = new ThreadPoolExecutor(2,
100, 1000, TimeUnit.MILLISECONDS
, new ArrayBlockingQueue<>(10));
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
es.submit(new MyThread());
}
}
static class MyThread implements Runnable {
@Override
public void run() {
for (; ; ) {
System.out.println("Thread name=" + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}如上面的代码所示,定义了一个初始容量为2,最大容量为100,队列长度为10的线程池,期待的运行结果为:
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-3
Thread name=pool-1-thread-4
Thread name=pool-1-thread-5
Thread name=pool-1-thread-6
Thread name=pool-1-thread-7
Thread name=pool-1-thread-8
Thread name=pool-1-thread-9
Thread name=pool-1-thread-10
Thread name=pool-1-thread-3
Thread name=pool-1-thread-5
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
Thread name=pool-1-thread-4
Thread name=pool-1-thread-10
Thread name=pool-1-thread-7
Thread name=pool-1-thread-6
Thread name=pool-1-thread-9
Thread name=pool-1-thread-8
Thread name=pool-1-thread-3
Thread name=pool-1-thread-4
Thread name=pool-1-thread-1
Thread name=pool-1-thread-5
Thread name=pool-1-thread-2
Thread name=pool-1-thread-8
Thread name=pool-1-thread-6
Thread name=pool-1-thread-7
Thread name=pool-1-thread-9
Thread name=pool-1-thread-10
期待十个线程都可以运行,但实际的执行效果如下:
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
Thread name=pool-1-thread-2
Thread name=pool-1-thread-1
对比可以看出,用上面的方式定义线程池,最终只有两个线程可以运行,即线程池的初始容量大小。其余线程都被阻塞到了队列ArrayBlockingQueue<>(10)
问题分析
我们知道,Executors框架提供了几种常见的线程池分别为:
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
如果将代码中自定义的线程池改为 :
private static ExecutorService es = Executors.newCachedThreadPool();运行发现,提交的十个线程都可以运行
Executors.newCachedThreadPool()的源码如下:
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}通过对比发现,newCachedThreadPool使用的是 SynchronousQueue<>()而我们使用的是ArrayBlockingQueue<>(10) 因此可以很容易的发现问题出在队列上。
问题解决
将ArrayBlockingQueue改为SynchronousQueue 问题解决,代码如下:
public class ExecutorTest {
private static ExecutorService es = new ThreadPoolExecutor(2,
100, 1000, TimeUnit.MILLISECONDS
, new SynchronousQueue<>());
private static ExecutorService es2 = Executors.newCachedThreadPool();
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
es.submit(new MyThread());
}
}
static class MyThread implements Runnable {
@Override
public void run() {
for (; ; ) {
System.out.println("Thread name=" + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}总结
两个队列的UML关系图
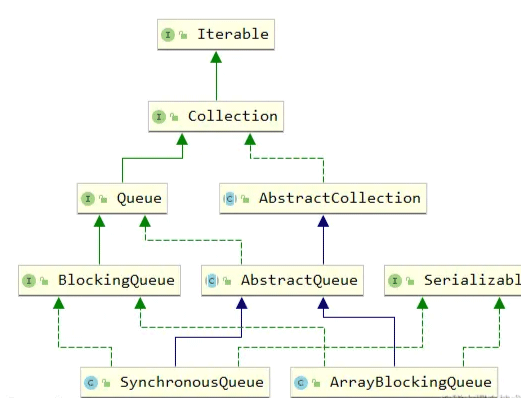
从图上我们可以看到,两个队列都继承了AbstractQueue实现了BlockingQueue接口,因此功能应该相似
SynchronousQueue的定义
* <p>Synchronous queues are similar to rendezvous channels used in
* CSP and Ada. They are well suited for handoff designs, in which an
* object running in one thread must sync up with an object running
* in another thread in order to hand it some information, event, or
* task.SynchronousQueue类似于一个传递通道,只是通过他传递某个元素,并没有任何容量,只有当第一个元素被取走,才能在给队列添加元素。
ArrayBlockingQueue的定义
* A bounded {@linkplain BlockingQueue blocking queue} backed by an
* array. This queue orders elements FIFO (first-in-first-out). The
* <em>head</em> of the queue is that element that has been on the
* queue the longest time. The <em>tail</em> of the queue is that
* element that has been on the queue the shortest time. New elements
* are inserted at the tail of the queue, and the queue retrieval
* operations obtain elements at the head of the queue.
ArrayBlockingQueue从定义来看就是一个普通的队列,先入先出,当队列为空时,获取数据的线程会被阻塞,当队列满时,添加队列的线程会被阻塞,直到队列可用。
分析
从上面队列的定义中可以看出,导致线程池没有按照预期运行的原因不是因为队列的问题,应该是关于线程池在提交任务时,从队列取数据的方式不同导致的。
jdk源码中关于线程池队列的说明
* <dt>Queuing</dt>
*
* <dd>Any {@link BlockingQueue} may be used to transfer and hold
* submitted tasks. The use of this queue interacts with pool sizing:
*
* <ul>
*
* <li> If fewer than corePoolSize threads are running, the Executor
* always prefers adding a new thread
* rather than queuing.</li>
*
* <li> If corePoolSize or more threads are running, the Executor
* always prefers queuing a request rather than adding a new
* thread.</li>
*
* <li> If a request cannot be queued, a new thread is created unless
* this would exceed maximumPoolSize, in which case, the task will be
* rejected.</li>从说明中可以看到,如果正在运行的线程数必初始容量corePoolSize小,那么Executor会从创建一个新线程去执行任务,如果正在执行的线程数必corePoolSize大,那么Executor会将新提交的任务放到阻塞队列,除非当队列的个数超过了队列的最大长度maxmiumPooSize。
从源码中找到关于提交任务的方法:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}从源码中看到 subimit实际上是调用了execute方法
execute方法的源码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}源码中可以看出,提交任务时,首先会判断正在执行的线程数是否小于corePoolSize,如果条件成立那么会直接创建线程并执行任务。如果条件不成立,且队列没有满,那么将任务放到队列,如果条件不成立但是队列满了,那么同样也新创建线程并执行任务。
到此这篇关于Java如何自定义线程池中队列的文章就介绍到这了,更多相关Java 队列内容请搜索编程学习网以前的文章希望大家以后多多支持编程学习网!
本文标题为:Java如何自定义线程池中队列


基础教程推荐








- 是否适合从javabean类更新数据库? 2023-11-04
- JavaWeb 实现验证码功能(demo) 2024-04-14
- 使用Java和WebSocket实现网页聊天室实例代码 2024-02-25
- 运用El表达式截取字符串/获取list的长度实例 2023-08-01
- Java编写实现窗体程序显示日历 2023-01-02
- 深入理解约瑟夫环的数学优化方法 2024-03-07
- Java+mysql实现学籍管理系统 2023-03-16
- JSP 动态树的实现 2023-12-17
- springboot下使用shiro自定义filter的个人经验分享 2024-02-27
- Java中EnvironmentAware 接口的作用 2023-01-23








